



2018年よりグーグルのエシカルAIチームをマーガレット・ミッチェル博士とともに率いてきたティムニット・ゲブル博士。グーグルは自主退職と主張するものの、博士は20年に発表した論文をきっかけにグーグルから突如解雇を言い渡されたという。解雇撤回を求める署名運動が巻き起こる事態に発展したが、21年に彼女は分散型AI研究所(DAIR)を設立。多くの期待が寄せられるゲブル博士にアルゴリズムバイアスの危険性とその対処法を尋ねた。

▲ティムニット・ゲブル/コンピュータ科学者。エチオピアに生まれ、幼少期に米国へ政治亡命する。スタンフォード大学で電子工学の学士と修士取得後、アップルでiPad第1世代の信号処理アルゴリズムを開発。スタンフォード大学に戻り、博士課程中に論文「ディープラーニングとグーグルストリートビューを用いて、全米の近隣地域の人口構成を予測する」で、2017年LDVキャピタル・ビジョン・サミット・コンペで優勝。マイクロソフトを経て、グーグルのエシカルAIチームをマーガレット・ミッチェル博士とともに率いた。21年ブラック・イン・AIと分散型AI研究所(DAIR)を創設。
データ分析の効能とそれに潜むバイアス
アルゴリズムバイアスとは、本来、正当と考えられているAIのアルゴリズムの結果には偏見が含まれ、公平性に欠けるだけでなく、新たな社会問題を引き起こしていることを指し、その改善の重要性が高まっている研究分野だ。
ティムニット・ゲブル博士は米国で活躍するコンピュータ科学者。専門はアルゴリズムバイアスとデータマイニングだが、彼女の名を一躍有名にした論文がある。スタンフォード大学在学中に共同研究を行った「ディープラーニングとグーグルストリートビューを用いて、全米の近隣地域の人口構成を予測する」(2017年)だ。米国政府は年間10億ドルをかけて国勢調査を実施しているが、ストリートビューに映る車種画像データを分析することで、その地域に住む人々の支持政党など、さまざまな志向が予測できるという画期的な研究内容だった。
「誰もがアクセスできるストリートビューのデータから、米国における人種間の分断や環境に対する考え方までを分析できることは大変意義深かったのです。同時にエシカルなAIについても深く考えるようになりました。なぜなら、この研究手法をそのまま用いて米国の犯罪率まで予測しようと考える人は必ず出てきます。ひじょうに危険でステレオタイプな結果が目に浮かぶ。私たちはデータをより用心深く扱うべきだと考えました」と当時を振り返る。
画像認識のアルゴリズムを通じて、AIが人種差別を拡大させたり、誤認逮捕を招く要因になってはならないという強い倫理観こそが、彼女がバイアスの研究に突き進んだ理由だろう。

▲50M GOOGLE STREET VIEW IMAGES
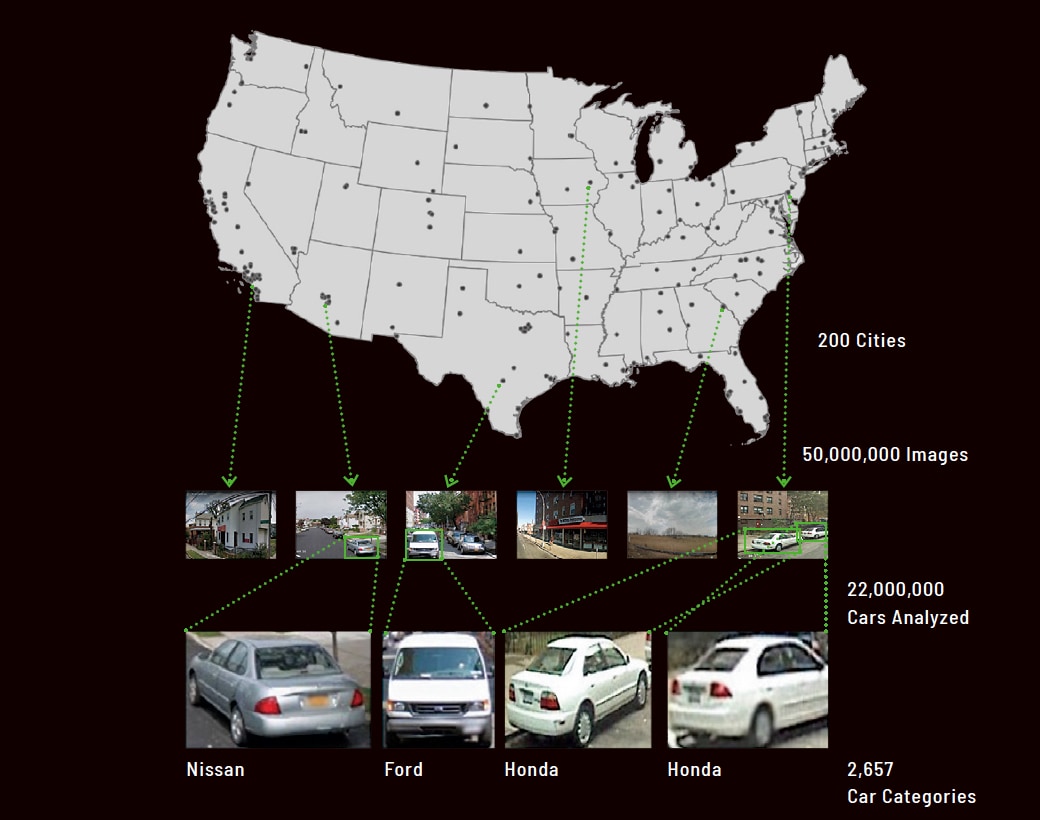
▲「ディープラーニングとグーグルストリートビューを用いて、全米の近隣地域の人口構成を予測する」。この論文でゲブル博士とそのチームは、200都市5,000万枚の画像データを解析し、2,200万台のクルマを2,657カテゴリーに分類した。
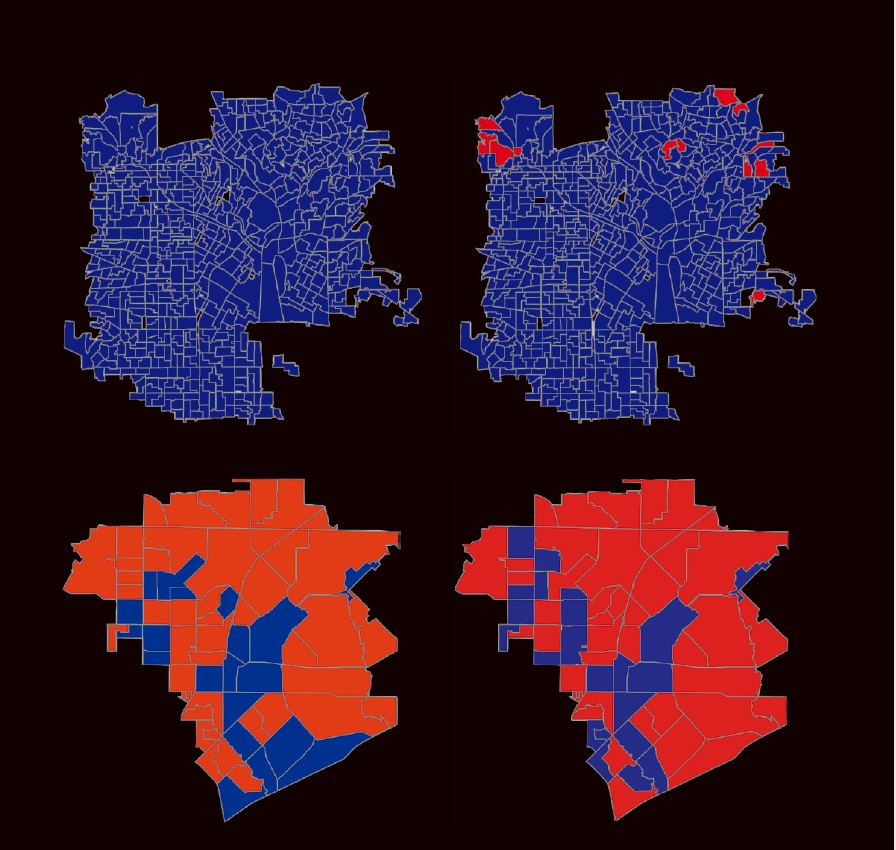
▲「ディープラーニングとグーグルストリートビューを用いて、全米の近隣地域の人口構成を予測する」より、支持政党の予測。カリフォルニア州ロサンゼルス(上)とテキサス州ガーランドの地図は、左が国勢調査、右がデータからの予測。赤が共和党、青が民主党支持者を示す。データから導いた結論と実際の選挙結果にほとんど差がないことが証明された。
アルゴリズムバイアスから自動化バイアスへ
ゲブル博士はアルゴリズムバイアスの多くは、人種、ジェンダー、マイノリティへの差別にあるという。例えば、米国では就職活動の際、履歴書に人種、性別などを記す項目を設けず、AIを用いていかに平等な採用過程かを謳う企業が増えている。しかし、その実情は、履歴書の情報からアルゴリズムを介して、企業の好まない人種や女性を自動的に排除し、面接にすら辿りつけないようにしているという。
アルゴリズムバイアスは、顔認識でも顕著に現れるそうだ。顔の色が濃くなればなるほど、認識率は下がり、ひどいときには人間として認識されない。しかも、この傾向は男性より女性に多く現れる。こう書くと、単純に顔認識ソフトウェアの性能を上げたり、監視カメラをいたるところに設置してデータ量を増やせばいいと考える人もいるだろうが、そんなに簡単な話ではない。
「ソフトウェアの性能向上は、皮膚の状態を解析するといった医療分野などではひじょうに意義があるでしょうが、根本的な解決策ではありません。そもそも、これまで情報量が少ないコミュニティやマイノリティの人々のデータを、正確かつ適切な方法で収集するのはひじょうに複雑な問題です。現在のウイグル族のように、迫害のために顔認証を取られることは人道的ではないでしょう。また、SNSの顔写真から得た個人情報を勝手にデータにされたら、プライバシーの侵害だと感じる人もいるはずです。しかも、収集したデータが正確ではないから、米国では警察の誤認逮捕が頻発しているのです」。ゲブル博士は日常に潜む監視についても批判的だ。
「アレクサやアマゾンエコーは、AI音声認識サービスと謳っていますが、実は、個人情報や家族の秘密をスピーカー越しにこっそり収集していると報告されています。私はこれらのサービスを絶対に使いませんが、この事実を知っても使い続ける人は多いのです。同時に、 自動化バイアスが強すぎる傾向も昨今の問題だと思います」。自動化バイアスとは、コンピュータが決定した事柄をそれがたとえ間違っていたとしても信じることを指すが、ここではAIが下した決定や情報を絶対だと鵜呑みにする人々の傾向を指している。

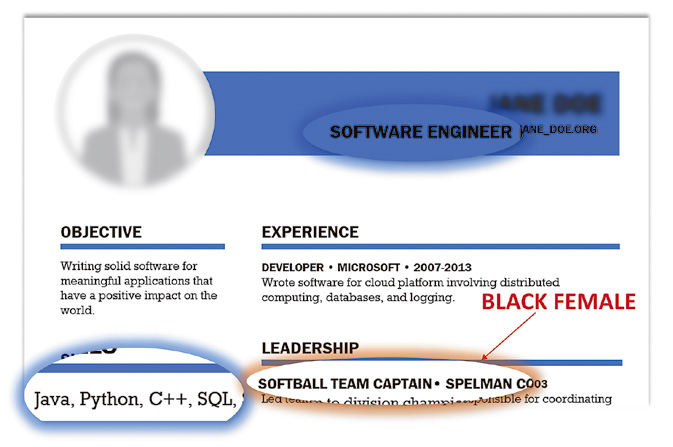
▲履歴書に性別や人種などは書かれていないが、AIは大学名やクラブ活動といった記述内容からそれらを読み取っていく。例えば、特定の人種が多い大学であるとか、ソフトボール部なら女性の確率が高いなど。©︎Adam Kalai
フェイクテキストを繰り返すAIというオウム
「自動化バイアスに陥る人が多い理由のひとつは、何でもかんでもAIという名の商品パッケージに仕立てあげ、ハイプ(誇大広告)な状態をつくり上げていくネット産業の問題が大きいと思います。実際にはAIとは名ばかりで、人間がAIのふりをしているだけだったという、とんでもない事例も報告されています。こうしたハイプに踊らされることなく、皆が、もう少しスローダウンしてAIを考えてほしいのです。ふたつ目は、リテラシーの欠如に他なりません。例えば、機械翻訳がつくり出す文章は、一見とても流暢です。不正確や不確実と感じさせる要素をいっさい人々に与えないことで、この翻訳文は100%完璧だと信じさせてしまう。これは恐ろしいことです」。
AIが虚偽を人に信じ込ませる事例は、機械翻訳に止まらない。ゲブル博士は「ディープフェイク」を例に挙げる。もともとは合成メディアとしてエンターテインメント分野で用いられていたが、女優や一般女性の顔をインスタグラムなどから切り取り、アダルトビデオの女優の顔とすり替えるといった悪用が多発。さらにAIがこれを量産し拡散する事件が多発している。
また、コロナ禍ではフェイクニュースが話題に上ったが、「東洋人がコロナの原因」とばかりにAIがつくったフェイクテキストがSNSで拡散された。根拠のない偏見に洗脳された人々による、東洋人への無差別な暴行事件は現在も米国各地で続く。これに日本人も巻き込 まれている。
2020年、グーグルのエシカルAIチームで活躍していたゲブル博士は、ワシントン大学の言語学教授エミリー・ベンダー他5名の研究者とともに、「確率変数のオウムの危険性について:言語モデルは大きくなり過ぎる可能性があるのか?」と題した論文の発表を試みた。
「オウムは聞いたことを繰り返すだけで、意味を理解しているわけではありません。現在、巷に流布する流暢なフェイクテキストは、このオウムから発せられていてそれ自体に意図はない。読んだ人々がフェイクニュースやヘイトスピーチ、危険思想に拡大していくのです」。オウムとは言わずもがなAIのことだ。
論文は、暴力的な言葉遣いや偏見に満ちた内容をチェックせず、ビッグデータからそのままマシンラーニングで言語処理させることの危険性などを論じた12ページほどの短いものだったが、これが博士がグーグルから去る端緒となってしまった。
バイアスを避ける方法とオルタナティブな研究
現在、EUではAI法を定めようという動きが活発だが、ユニバーサルなAIのルールはまだ存在しない。ほぼ無法状態のAIをゲブル博士はクルマの歴史になぞらえる。
「スピード制限もシートベルトも道路交通法すらもなかった時代から今に至るまでには、長い年月が必要でした。AIもクルマと同様の過程を辿ることでしょう。ただ、規則や人々の合意が定まるまで、私たちは何もしないわけにはいきません。事前にバイアスを取り除かなければ、常にデータ内にバイアスが存在し続けるからです」と語り、対処法としてふたつのアプローチを挙げる。
ひとつは、技術的なアプローチだ。技術者はハードウェアやソフトウェアを開発したとき、必ずそのスペックを明示するが、同様にデータ解析時に目的を明確に記していく。これにより、データが当初の目的以外に勝手に使用されることを防げる。
ふたつ目はホリスティックなアプローチで、データ自体に注釈を加えていくことだ。従来アーキビストはキュレーションというひじょうに重要なスキルを熟知している。データ管理において、アーカイブのような完璧なキュレーションは必要ないが、データの中身を理解して、整理するという行為やそれを行う人の存在が重要になる。
「他分野のプロから学ぶ姿勢は大切です。例えば、歴史家は、人々がデータやバイアスにどのように対処してきたかを研究しているからです」と語るゲブル博士は、2021年末に分散型AI研究所(DAIR)を設立した。
「研究の裏に大企業が潜んでいると、彼らに不都合な事実は公表できないものです。研究自体が企業のプロパガンダとなる危険もはらんでいる。DAIRはオルタナティブなAIの研究機関として存在する意味があると信じています」。

▲DAIRでは、南アフリカのアパルトヘイト撤廃が近隣市町村にもたらした影響とその変化を航空写真から分析する。左が2011年、右が17年。大型ショッピングモールのある裕福な地域で、富裕層の住宅地をグレーで示す。
©Raesetje Sefala
彼女は最後にこう締めくくる。「米国にほとんど公共交通がない理由はなぜでしょう?なぜクルマ社会なのでしょう?」ゲブル博士は、 ビッグテックにAIを任せきりにしたら、将来何が起こるかを考えるのは今だと、われわれに語りかけている。![]()
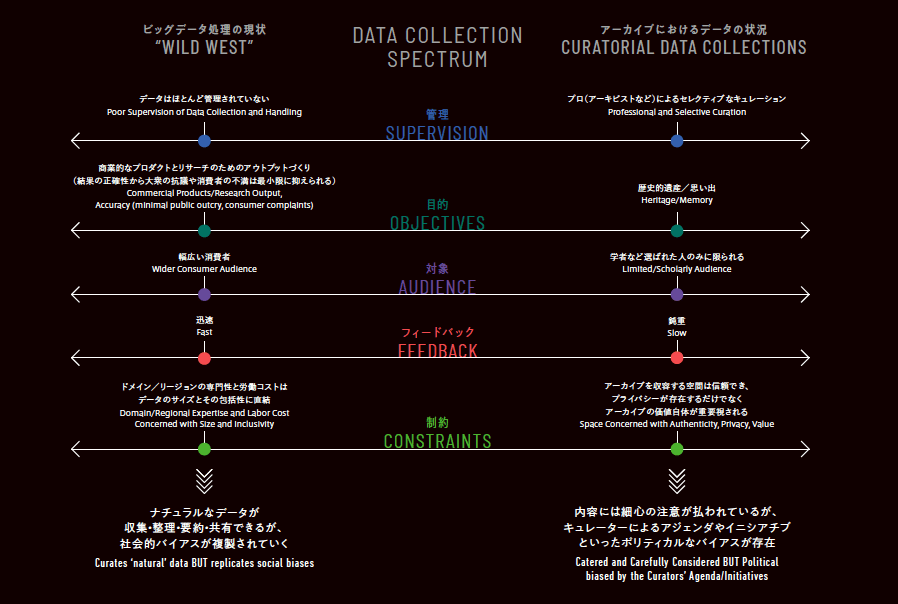
▲データコレクションのスペクトラム。データとアーカイブは異なる性質だが、バランス感覚を大切にし、互いの良い面を引き出すことでデータ解析は良い結果をもたらすことを示している。
本記事はデザイン誌「AXIS」216号「再び、オフィスへ。」(2022年4月号)からの転載です。

デザイン誌「AXIS」216号(2022年4月号)
再び、オフィスへ。
オフィスワークとリモートワークを併用しながら働くハイブリッドなワークスタイルが「新たな日常」として定着しつつあるなか、働く場=オフィスという定義にとどまらず、ワーカーのニーズの変化も踏まえて、これからのオフィスに求められる視点や社会とオフィスの新たな距離感などを考えます。

中島恭子(なかじま・きょうこ)/ライター
日本女子大学文学部英米文学科卒業。第一勧業銀行(現みずほ銀行)勤務後、セントラル・セント・マーチンズ・カレッジ・オブ・アーツ&デザインでデザインスタディ修士取得。現在、英国在住。趣味はパフォーマンス鑑賞と自由旅行。近年、面白かったのは「バーニングマン」とナミビアをレンタカーで周遊したこと。最近の興味はテクノロジーの行方。デザイン誌「AXIS」にはオラファー・エリアソンやグーグルのクリエイティブ・ディレクターのインタビューなどを寄稿。





